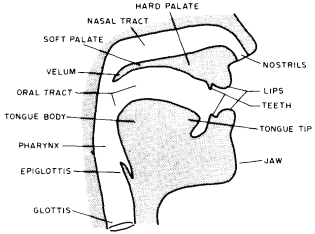
Figure 1: The Human Vocal Tract. The human vocal tract is roughly described us a tube approximately 17.4 cm long with varying resonance characteristics as muscles control the shape. The tract splits into Two parts, nasal and oral, at the top, with a valve called the velum providing flexible control of the nasal resonances in given utterance. An electronic model of this natural organ roughly parallels the function of the tract. |
You've got your microcomputer running and you invite your friends in to show off the new toy. You ask Charlie to sit down and type in his name. When he does, a loudspeaker on the shelf booms out a hearty '' Hello, Charlie! '' Charlie then starts a game of Star Trek and as he warps around thru the galaxy searching for invaders, each alarming new development is announced by the ship's computer in a warning voice, "shieid power low ! '' "Torpedo damage on lower decks! '' The device that makes this possible is a peripheral with truly unlimited applications, the speech synthesizer. This article describes what a speech synthesizer is like, how it works and a general outline of how to I control it with a microcomputer. We will look at the structure of human speech and see how that structure can be generated by a computer controlled device.
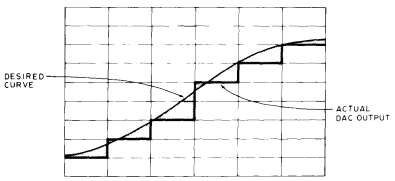
Figure 2: DAC Quantization Errors. The actual output of a computer to the analog world is a step function (in the absence of any filtering). This leads to the problem of quantization errors, depicted conceptually here by the Shaded areas in between the smooth analog function and its closest step function approximation. Low precision digital to analog conversions accentuate this problem. |
How can you generate Speech sounds artificially, under computer control ? Let's look at some of the alternatives. Simplest of all, with a fast enough digal to analog converter (DAC) you can generate any sound you like. A 7 or 8 bit DAC can produce good quality sound, while some- where around 4 or 5 bits the quantization noise starts to be bothersome. This noise is produced because with a 5 bit data value it is possible to represent only 32 discrete steps or voltage levels at the converted analog output. Instead of a smoothly rising voltage slope, you would get a series of steps as in figure 2. As for the speed of the DAC, a conversion rate of 8,000 to 1 0,000 conversions per second [ The sample rate in conversions per second or samples per second is often quoted in units of Hertz. We will use that terminology here, although conversions per second is a generalization of the concept of cycles per second ] is sufficient for fairly good quality speech. With sample rates below about 6 kHz the speech quality begins to deteriorate badly because of inadequate frequency response.
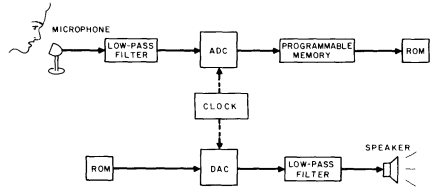
Figure 3: Waveform Playback from ROM Storage. One way to achieve a digitally controlled vocal output is to first digitize a passage of human speech) then store the digital pattern in memory. For a commercial product, such as a talking calculator, the limited vocabulary required makes this a feasible avenue of design, especially when a single mass produced ROM can be used in the final product. In an experimenter's system, the ROM is not needed, and programmable memory can be substituted during experiments. This is probably the least expensive way to augment an existing computer's capability with vocal output, but the memory requirements limit its use to Small vocabularies. The quality of the result varies with the ADC (and DAC) sampling rate and precision. |
Almost any microprocessor can easily handle the data rates described above to keep the DAC going. The next question is, where do the samples come from? One way to get them would be by sampling a real speech signal with a matching analog to digital converter (ADC) running at the same sample rate. You then have a complicated and expensive, but very flexible, recording System. Each second of speech requires 8 K to 10 K bytes of storage. If you want only a few words or short phrases, you could store the samples on a ROM or two and dump then sequentially to the DAC. Such a system appears in figure 3.
If you want more than a second or two of speech output, however, the amount of ROM storage required quickly becomes impractical. What can be done to minimize storage? Many words appear to have parts that could be recombined in different ways to make other words. Could a lot of memory be saved this way? A given vowel sound normally consists of several repetitions of nearly identical waveform segments with the period of repetition corresponding to the speech fundamental frequency or pitch.
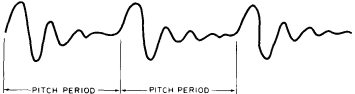
Figure 4: Typical Vowel Waveform. In principle, a vowel is a fairly long sustained passage of sound with repetitive characteristics. The vowel sounds are produced physiologically by the resonances of the vocal tracts, and are controlled electronically by the formant filters which produce the equivalent of vocal tract resonances. |
Figure 4 shows such a waveform. Within limits, an acceptable sound is produced if we store only one such cycle and construct the vowel sound by repeating this waveform cycle for the duration of the desired vowel.
Of course, the pitch will be precisely constant over that entire interval. This will sound rather unnatural, especially for longer vowel durations, because the period of repetition in a naturally spoken vowel is never precisely constant, but fluctuates slightly. In natural speech the pitch is nearly always changing, whether drifting slowly or sweeping rapidly to a new level. It is of interest that this jitter and movement of the pitch rate has a direct effect on the perception of speech because of the harmonic structure of the speech signal. In fact, accurate and realistic modelling of the natural pitch structure is probably the one most important ingredient of good quality synthetic speech. In order to have smooth pitch changes across whole sentences, the number of separate stored waveform cycles still gets unreasonable very quickly. From these observations of the cyclic nature of vowels, let us move in for a closer look at the structure of the speech signal and explore more sophisticated possibilities for generating synthetic speech.
The human vocal tract consists of an air filled tube about 16 to 18 cm long, together with several connected structures which make the air in the tube respond in different ways (see figure 1). The tube begins at the
vocal cords, or glottis, where the flow of air up from the lungs is broken up into a series of sharp pulses of air by the vibration of the vocal cords. Each time the glottis snaps shut, ending the driving pulse with a rapidly falling edge, the air in the tube above vibrates or rings for a few thousandths of a second. The glottis then opens and the airflow starts again, setting up conditions for the next cycle.
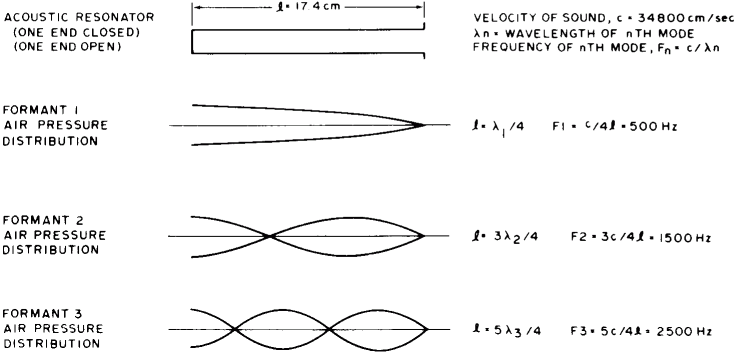
The length of this vibrating air column is the distance from the closed glottis up along the length of the tongue and ending at the lips, where the air vibrations are coupled to the surrounding air. If we now consider the frequency response of such a column of air, we see that it vibrates in several modes or resonant frequencies corresponding to different multiples of the acoustic quarter wavelength. There is a strong resonance or energy peak at a frequency such that the length of the tube is one quarter wavelength, another energy peak where the tube is three quarter wavelengths, and so on at every odd multiple of the quarter wavelength. If a tube 17.4 cm long had a constant diameter from bottom to top, these resonant energy peaks would have frequencies of 500 Hz, 1500 Hz, 2500 Hz and so on. These resonant energy peaks are known as the formant frequencies. Figure 5 illustrates the simple acoustic resonator and related physical equations.
Figure 5: Tube Resonances. Temporarily ignore the complicated shape of the vocal tract and simplify it to a tube 17.4 cm long. Applying the equations of physics to acoustic waves in air gives resonances at several modes or natural frequencies. The standing waves along the tube at each frequency are shown, and identified as formant 1, formant 2 and formant 3. In the actual vocal tract, a more complicated and time varying geometry changes the resonances as a sound is created. |
|
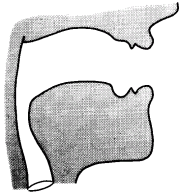
Figure 6: "ah" as in "father." In figure 1, the vocal tract was shown in schematic form. Here is a similar figure showing how the tract has been modified to produce the vowel sound "ah." The human typically closes off the nasal cavity and widens out the oral cavity by opening the mouth during this sound. |
|
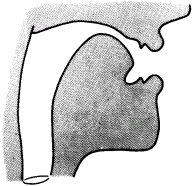
Figure 7: "ee" as in "heed" In contrast to figure 6 when the "ee" vowel sound is created, the mouth opening tends to be narrowed; and the upper end of the vocal tract is restricted This lowers the frequency of the first resonant mode and raises the frequencies of the second and third. Referring to table 1, the "ee" vowel sound has some of the highest resonances for formants F2 and F3 and the lowest for Fl. |
The vocal tract tube, however, does not have a constant diameter from one end to the other. Since the tube does not have constant shape, the resonances are not fixed at 1000 Hz intervals as described above, but can be swept higher or lower according to the shape. When you move your tongue down to say "ah," as in figure 6, the back part is pushed back toward the walls of the throat and in the front part of the mouth the size of the opening is increased. The effect of changing the shape of the tube in this way is to raise the frequency of the first resonance or formant 1 (F1) by several hundred Hz, while the frequency of formant 2 (F2) is lowered slightly. On the other hand, if you move your tongue forward and upward to say "ee," as in figure 7, the size of the tube at the front, just behind the teeth, is much Smaller, while at the back the tongue has been pulled away from the walls of the throat, leaving a large resonant cavity in that region. This results In a sharp drop in F1 down to as low as 200 or 250 Hz, with F2 being increased to as much as 2200 or 2300 Hz.
We now have enough information to put together the circuit for the oral tract branch of a basic formant frequency synthesizer. After discussing that circuit, we will continue on in this way, describing additional properties of the speech mechanism and building up the remaining branches of the synthesizer circuit.
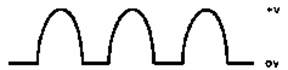
Figure 8: Voiced Sounds from the Glottis. Sounds which have definite pitch are called voiced sounds. In the natural larynx, these sounds are generated by the vocal chords and drive the vocal tract at the glottis. In an electronic analog, the voiced sounds can be generated by a programmable counter (to set the frequency) which in turn creates a sine wave of the same frequency. A rectified sine wave is a good source for the glottal pulses used in the electronic model of a larynx used in the author's approach to speech generation. |
To start with, we must have a train of driving pulses, known as the voicing source, which represents the pulses of air flowing up thru the vibrating glottis. This could be simply a rectified sine wave as in figure 8. To get different voice qualities, the circuit may be modified to generate different waveform shapes.
This glottal pulse is then fed to a sequence of resonators which represent the formant frequency resonances of the vocal tract. These could be simple operational amplifier bandpass filters which are tunable over the range of each respective formant.
Figure 9 shows the concept of a typical resonator circuit which meets our requirements. IC1, IC2 and IC4 form the actual bandpass filter, while lC3 acts as a digitally controlled resistance element serving to vary the resonant frequency of the filter. Several such resonator circuits are then combined as in figure 10 to form the vocal tract simulator. The voicing amplitude control, AV, is another digitally controlled resistance similar to IC3 of figure 9.
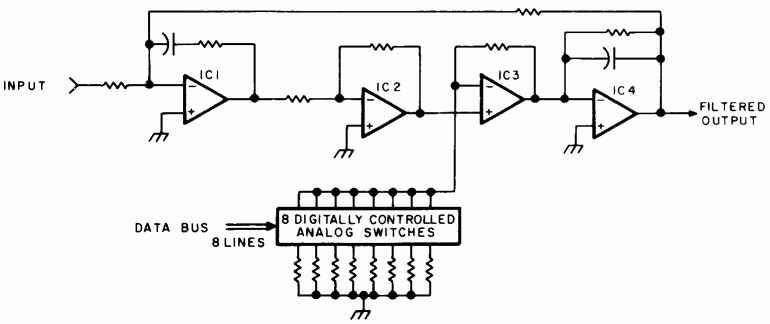
Figure 9: Typical Formant Resonator Circuit. A digitally controlled band pass filter can be built from four operational amplifiers and 8 digitally controlled analog switches. The filter characteristics are set by the choice of the resistance and capacitance elements as well as the digital control word. The operational amplifier IC3 serves as a gain controlled amplifier in the feedback loop) which alters the filter resonance. |
This gain controlled amplifier configuration is the means by which the digital computer achieves its control of speech signal elements. The data of one byte drives the switches to set the gain level of the amplifier in question. In figures 10, 13 and 15 of this article, this same variable resistance under digital control is shown symbolically as a resistor with a parameter name, rather than as an operational amplifier with analog switches.
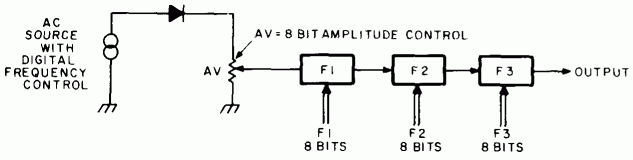
Figure 10: A first approximation of the voice synthesizer can be constructed by using three formant filters in series with differing resonance settings all controlled by 8 bit digital words. The resistance indicated as AV is an operational amplifier circuit (see IC3 of figure 9) with a digital gain control input. It is thus a programmable element of gain less than unity in other words the electronically controlled equivalent of a variable resistance. This notation of a controlled resistance is used in figures 13 and 15 as well. |
The vocal tract circuit as shown thus far is sufficient to generate any vowel sound in any human language (no porpoise talk, yet). Most of the vowels of American English can be produced by fixed, steady state formant frequencies as given in table 1. A common word is given to clearly identify each vowel. The formant frequency values shown here may occasionally be modified by adjacent consonants.
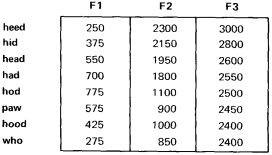 |
Table l: Steady State English Vowels The vowel sounds are made by adjusting the formant resonances of the human vocal tract to the frequencies listed in this table. These figures are approximate, and actual formant resonances vary from individual to individual. In a speech synthesizer based upon an electronic model of the vocal tract, the formant frequencies are set digitally using operational amplifier filters with adjustable resonant peaks. |
An alternative way to describe the formant relationships among the vowels is by plotting formant frequencies F1 vs F2 as in figure 11. F3 is not shown here because it varies only slightly for all vowels (except those with very high F2, where it is somewhat higher).
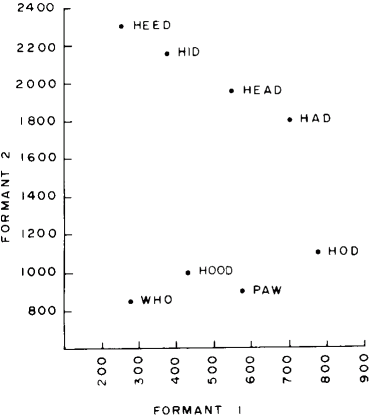 Figure 11: The Steady State English vowels. The distinctions between various
vowel sounds can be illustrated by plotting them on a two dimensional graph.
The horizontal axis is the formant 1 frequency, the vertical axis is the
formant 2 frequency. A location for each vowel utterance can be determined
experimentally by locating the resonance peaks with an audio spectrum
analyzer.
Figure 11: The Steady State English vowels. The distinctions between various
vowel sounds can be illustrated by plotting them on a two dimensional graph.
The horizontal axis is the formant 1 frequency, the vertical axis is the
formant 2 frequency. A location for each vowel utterance can be determined
experimentally by locating the resonance peaks with an audio spectrum
analyzer. |
The F1 -F2 plot provides a convenient space in which to study the effects of different dialects and different languages. For example, in some sections of the United States, the vowels in "hod" and "paw" are pronounced the same, just above and to the right of "paw" on the graph. Also, many people from the western states pronounce the sounds in "head" and "hid" alike about halfway between the two points plotted for these vowels on the graph.
A few English vowels are characterized by rapid sweeps across the formant frequency space rather than the relatively stable positions of those given in table 1. These sweeps are produced by moving the tongue rapidly from one position to another during the production of that vowel sound. Approximate traces of the frequency sweeps of formants F1 and F2 are shown in figure 12 for the vowels in "bay" "be" "buy," "hoe" and "how." These sweeps occur in 150 to 250 ms roughly depending on the speaking rate.
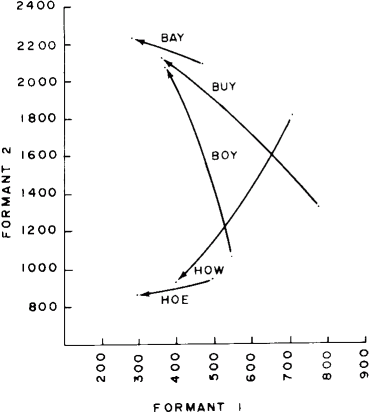 Figure 12: English Diphthongs. A diphthong is a sound which represents a
smooth transition from one vowel sound to another during an utterance. The
time duration of the swap from one point to another in formant space is typically
150 to 250 ms. This graph shows typical starting and ending points for several
common diphthong sounds.
Figure 12: English Diphthongs. A diphthong is a sound which represents a
smooth transition from one vowel sound to another during an utterance. The
time duration of the swap from one point to another in formant space is typically
150 to 250 ms. This graph shows typical starting and ending points for several
common diphthong sounds. |
Consonant sounds consist mostly of various pops, hisses and interruptions imposed on the vibrating column of air by the actions of several components of the vocal tract shown in figure 1. We will divide them into four classes: 1) stops, 2) liquids, 3) nasals, and 4) fricatives and affricates. Considering first the basic 'stop consonants' "p," "t," "k," "b," "d" and "g" the air stream is closed off, or stopped, momentarily at some point along its length, either at the lips, by the tongue tip just behind the teeth or by the tongue body touching the soft palate near the velum. Stopping the air flow briefly has the effect of producing a short period of silence or near silence, followed by a pulse of noise as the burst of air rushes out of the narrow opening.
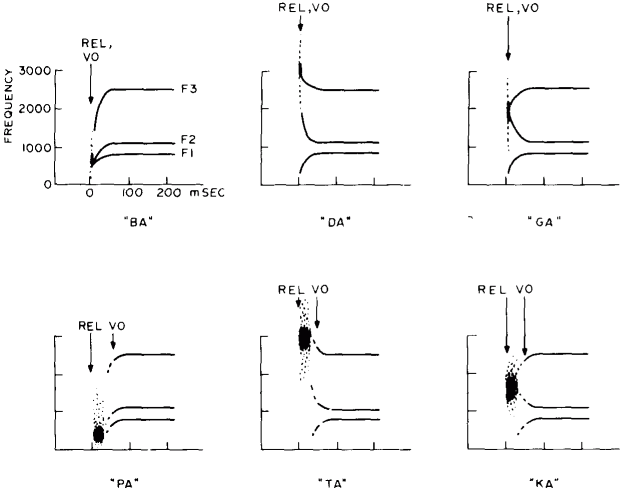
Figure 14: Stop Consonant Patterns. This figure illustrates 6 different stop consonant patterns. The release of the stop closure (start of noise pulse) is at the point marked by "Rel" and the bringing of the voicing sounds is marked by "VO" Note the typical transition of the vowel formants as the steady state is reached. |
The shape of the vocal tract with the narrow opening at different points deter- mines the spectral shape of the noise pulse as well as the formant locations when voicing is started. Both the noise burst spectrum and the rapid sweeps of formant frequency as the F1-F2 point moves into position for the following vowel are perceived as characteristic cues to the location of the tongue as the stop closure is released. We need only add a digitally controlled noise generator to the vocal tract circuit of figure 10 to simulate the noise of the burst of air at the closure release and we can then generate all the stop consonants as well as the vowels. Figure 13 shows the speech synthesizer with such a noise generator added. The breakdown noise of a zener diode is amplified by IC1 and amplitude is set by the digitally controlled resistor AH. IC2 is a mixer amplifier which combines the glottal source and aspiration noise at the input to the formant resonators.
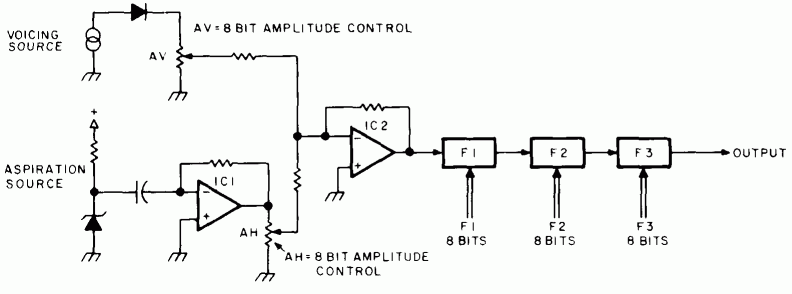
Figure 13: Synthesizer with Aspiration Noise Generator. Not all utterances are vowels. By adding a digitally controlled noise generator to the circuit of figure 10, it is possible to synthesize the consonant sounds known as "stops." In this circuit, the amplitude versus time characteristics of the noise pulse are determined by an 8 bit programmable gain control AH (shown symbolically as a resistor). The output of the noise source is mixed with the voicing source with the analog sum being routed to the formant filters. The noise generator is a zener diode. |
It is important to notice at this point the range of different sounds that can be generated by Small changes in the relative timing of the control parameters. The most useful of these timing details is the relationship between the pulse of aspiration noise and a sharp increase in the amplitude of voicing (see figure 14). For example, if we set the noise generator to come on for a noise pulse about 40 ms long and immediately after this pulse, F1 sweeps rapidly from 300 up to 775 Hz and F2 moves from 2000 down to 1100 Hz, the sound generated will correspond to moving the tip of the tongue down rapidly from the roof of the mouth.
Observe, however, that the formant output is silent after the noise pulse until the voicing amplitude is turned up. If voicing is turned on before or during a short noise burst, the circuit generates the sound "da," whereas if the voicing comes on later, after a longer burst and during the formant frequency sweeps, the output sounds like "ta."
This same timing distinction characterizes the sounds "ba" vs "pa" and "ga" vs "ka," as well as several other pairs which we will explore later. Figure 14 gives the formant frequency patterns needed to produce all the stop consonants when followed by the vowel "ah." When the consonant is followed by a different vowel the formants must move to different positions corresponding to that vowel.
The important thing to note about a stop transition is that the starting points of the frequency sweeps correspond to the point of closure in the vocal tract, even though these sweeps may be partially silent for the unvoiced stops "p," "t" and "k" here the voicing amplitude comes on after the sweep has begun.
The second consonant group comprises the liquids "w," "y," "r" and "l." These sounds are actually more like vowels than any of the other consonants except that the timing of formant movements is crucial to the liquid quality. "W" and "y" can be associated with the vowels "oo" and "ee," respectively. The difference is one of timing.
If the vowel "oo" is immediately followed by the vowel "ah," and then the rate of F1 and F2 transitions is increased, the result will sound like "wa." A comparison of the resulting traces of F1 and F2 vs time in "wa" with the transition pattern for "ba" in figure 14 points out a further similarity. The direction of movement is basically the same, only the rate of transition of "ba" is still faster than for "wa." Thus we see the parallelism in the acoustic signal due to the common factor of lip closeness in the three sounds "ua," "wa" and "ba." "Y" can be compared with the vowel "ee" in the same way, so the difference between "ia" and "ya" is only a matter of transition rates. Generally, "l" is marked by a brief increase of F3, while "r" is indicated by a sharp drop in F3, in many Cases, almost to the level of F2.
The third group of consonants consists of the nasals "m," "n" and "ng." These are very similar to the related voiced stops "b," "d" and "g" respectively, except for the addition of a fixed "nasal formants." This extra formant is most easily generated by an additional resonator tuned to approximately 1400 Hz and having a fairly wide bandwidth. It is only necessary to control the amplitude of this extra resonator during the "closure" period to achieve the nasal quality in the synthesizer output.
The fourth series of consonants to be described are the fricatives, "s," "sh," "z," "zh," "f," "v" and "th" and the related affricates "ch" and "j." The affricates "ch" and "j" consist of the patterns for "t" and "d" followed immediately by the fricative "sh" or "zh," respectively that is "ch" = "t+sh" and "j" = "d+z" The sound "zh" is otherwise rare in English. An example occurs in the word "azure." With the letters "th," two different sounds are represented, as contained in the words "then" and "thin."
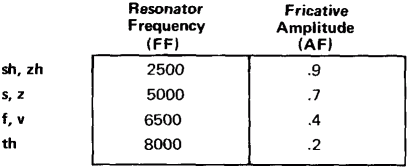
Table 2: Fricative Spectra. A fricative sound typically consists of a pulse of high frequency noise. The various types of fricatives are classified according to the spectral profile of the pulse. For the electronic model described here, the fricative amplitude and resonator frequency for several sounds are listed in this table. |
All the fricatives are characterized by a pulse of high frequency noise lasting from 50 to 150 msec. The first subclassification of fricatives is according to voicing amplitude during the noise pulse, just as previously described for the stop consonants. Thus "s," "sh," "f," "ch" and "th" and in "thin" have no voicing during the noise pulse while "z," "zh," "v," "j" and "th" as in "then" have high voice amplitude. When a voiceless fricative is followed by a vowel, the voicing comes on during the formant sweeps to the vowel position, just as in the case of the voiceless stops. The different fricatives with- in each voice group are distinguished by the spectral characteristics of the fricative noise pulse. This noise signal differs from that previously described for the stop bursts in that it does not go thru the formant resonators, but is mixed directly into the output after spectral shaping by a single pole filter. Table 2 gives the fricative resonator settings needed to produce the various fricative and affricate consonants. Fricative noise amplitude settings are shown on a scale of 0 to 1.
The system level diagram of a complete synthesizer for voice outputs is summarized in figure 15.
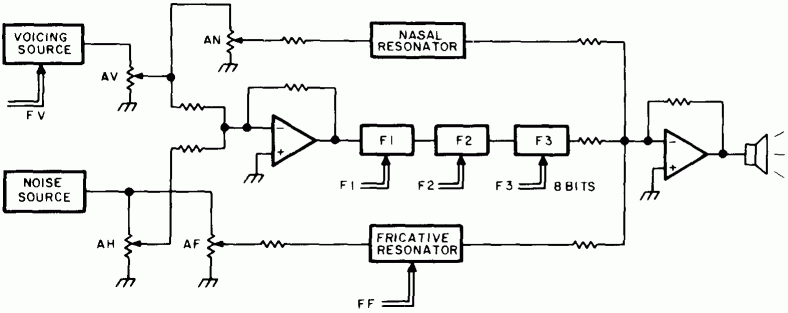
Figure 15: The Complete Synthesizer. This diagram shows the organization of a complete synthesizer which includes a wide variety of parameters. The voicing frequency and amplitude are set by parameters FV and AV. The noise pulses of stop consonants are generated with the programmable gain element AH. The fricative resonator with amplitude AF and frequency resonance FF are used to generate fricatives like "s" and "sh." The normal vowel sounds are generated by control of the formant frequencies Fl, F2 and F3, and a nasal resonator with amplitude AN and fixed frequency characteristics is used to add varying amounts of nasal sounds. The result of signals processed through the nasal, formant and fricative paths is summed by a final operational amplifier and used to drive the output speaker. |
The information contained in this article should be sufficiently complete for individual readers to begin experimenting with the circuitry needed to produce speech outputs. In constructing a synthesizer on this model, the result will be a device which is controlled in real time by the following parameters:
AV = amplitude of the voicing source, 8 bits
FV = frequency of the voicing source, 8 bits
AH = amplitude of the aspiration noise component, 8 bits
AN = amplitude of the nasal resonator component, 8 bits
AF = amplitude of the fricative noise component, 8 bits
F1 = frequency of the formant 1 filter, 8 bit setting.
F2 = frequency of the formant 2 filter, 8 bit setting.
F3 = frequency of the formant 3 filter, 8 bit setting.
FF = frequency of fricative resonator filter, 8 bit setting.
This is the basic hardware of a system to synthesize Sound; in order to complete the system, a set of detailed time series for settings for these parameters must be deter- mined (by a combination of the theory in this article and references, plus experiment with the hardware). Then, software must be written for your own computer to present the right time series of settings for each sound you want to produce. Commercial synthesizers often come with a predefined set of "phonemes" which are accessed by an appropriate binary code. The problem of creating and documenting such a set of phonemes is beyond the scope of this introductory article, but is well within the dollar and time budgets of an experimenter.
At the time this article goes to press, a synthesizer module incorporating several detail refinements and improvements over the circuits of this article is being developed by the author and associates. A detailed user's guide will be supplied with the Computalker module which illustrates the timing relation- ships needed to produce all the consonant-vowel and vowel-consonant combinations which occur in natural speech.
This can serve as a reference guide for creating your speech output software which gener- ates the proper control patterns from text inputs. Write to
Computalker, 821 Pacific St No. 4. Santa Monica CA 90405
for the latest informtion on this module.
1. Erman, Lee, ed, IEEE Symposium on speech recognition, April. 1974, Contributed Papers, IEEE Catalog No. 74CH0878-9 AE.
2. Flanagan, J L, and Rabiner, L R, eds, speech
Svnthesis, Benchmark Papers in Acoustics,
Dowden, Hutchison & Ross, Inc, 1973.
3. Lehiste. IIse, ed, Readings in Acoustic Phonetics.
MIT Press, 1967.
4. Moschytz, George S. Linear Integrated Net-
works Design. Van Nostrand, New York, 1975.
See also:
| file: /Techref/new/letter/speech1.htm, 32KB, , updated: 2005/6/4 22:34, local time: 2025/7/8 23:23,
216.73.216.54,10-2-23-56:LOG IN
|
| ©2025 These pages are served without commercial sponsorship. (No popup ads, etc...).Bandwidth abuse increases hosting cost forcing sponsorship or shutdown. This server aggressively defends against automated copying for any reason including offline viewing, duplication, etc... Please respect this requirement and DO NOT RIP THIS SITE. Questions? <A HREF="http://www.massmind.org/techref/new/letter/speech1.htm?key=Small%20Cases"> </A> |
| Did you find what you needed? "Small Cases" |
Welcome to massmind.org! |
Welcome to www.massmind.org! |
.